-

- Co-Staff

11 Nov 2014 12:41
Hola
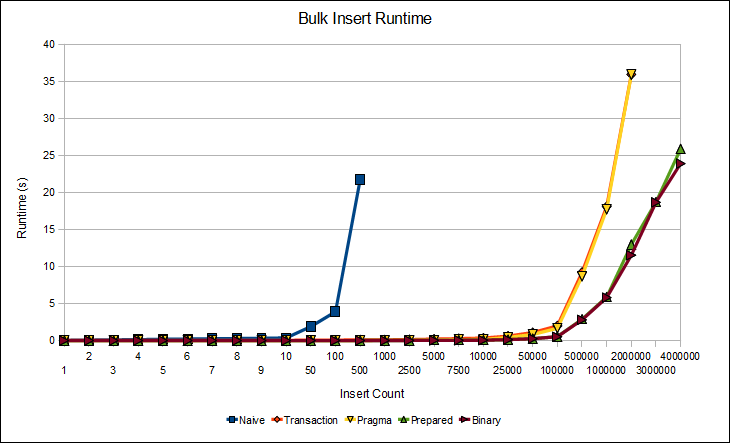
He estado mirando las ayudas de las 2 versiones para actualizar un proyecto hecho con sqlite 2.x a 3, pero tengo la duda siguiente porque no lo termino de ver claro, en sqlite 2 existia la funcion "sqlite.querytotable" y en sqlite 3 no existe esto. ¿Esta funcion podria ser el equivalente a esta funcion de sqlite 3 "stmt:prepare" (que es algo asi como preparar sentencias sqlite para su uso en multiples veces a lo largo del codigo? Si no es asi con que comando se corresponderia?
He estado mirando las ayudas de las 2 versiones para actualizar un proyecto hecho con sqlite 2.x a 3, pero tengo la duda siguiente porque no lo termino de ver claro, en sqlite 2 existia la funcion "sqlite.querytotable" y en sqlite 3 no existe esto. ¿Esta funcion podria ser el equivalente a esta funcion de sqlite 3 "stmt:prepare" (que es algo asi como preparar sentencias sqlite para su uso en multiples veces a lo largo del codigo? Si no es asi con que comando se corresponderia?